
Scheduling & Dependencies
How to set up schedules and run transforms with dependencies
Basics
One of the fundamental parts of the application is the ability to run SQL transforms and have them execute when their upstream dependencies have been met. On paper this seems relatively straightforward, but diving a bit deeper uncovers a lot of complexities.
Upstream/Downstream Dependencies
There are 2 types of dependencies, the tables which are required to read the data from (upstream) and then the table/s which the data is written to (downstream). Take this for example:
create or replace table transforms.order_shipping AS
select
s.date,
s.order_number,
s.quantity,
s.item,
c.name,
c.address
from transforms.orders s
JOIN transforms.customers c
on s.ship_to_customer_sk = c.customer_sk;The upstream tables are transforms.orders and transforms.customers, and the downstream table is transforms.order_shipping. This means that before the transform can be run, the customer and order tables need to be present. Sometimes the upstream dependency is created outside of the transforms and sometimes it’s created in a transform. We only need to be concerned about the ones created by transforms, if one of the dependencies is a static lookup table, we can’t attach a dependency to it.
Scheduling & Dependency Basics
When we schedule our transforms, they may not all run at the same time, some of the transforms may require data which isn’t available until after a certain time. For example, Google Analytics data for the previous day is available in the API at 03:00, but the same data in Big Query isn’t available until later. Depending on the volume, it could be mid-morning. Data for the previous day from internal systems or eCommerce APIs is generally available close to midnight. Due to the differences in timings, some companies will run parts of their ETL at different times which means that we need to run only those transforms where the dependencies have been met and there are no transforms scheduled to run in the future.
A basic DAG example:
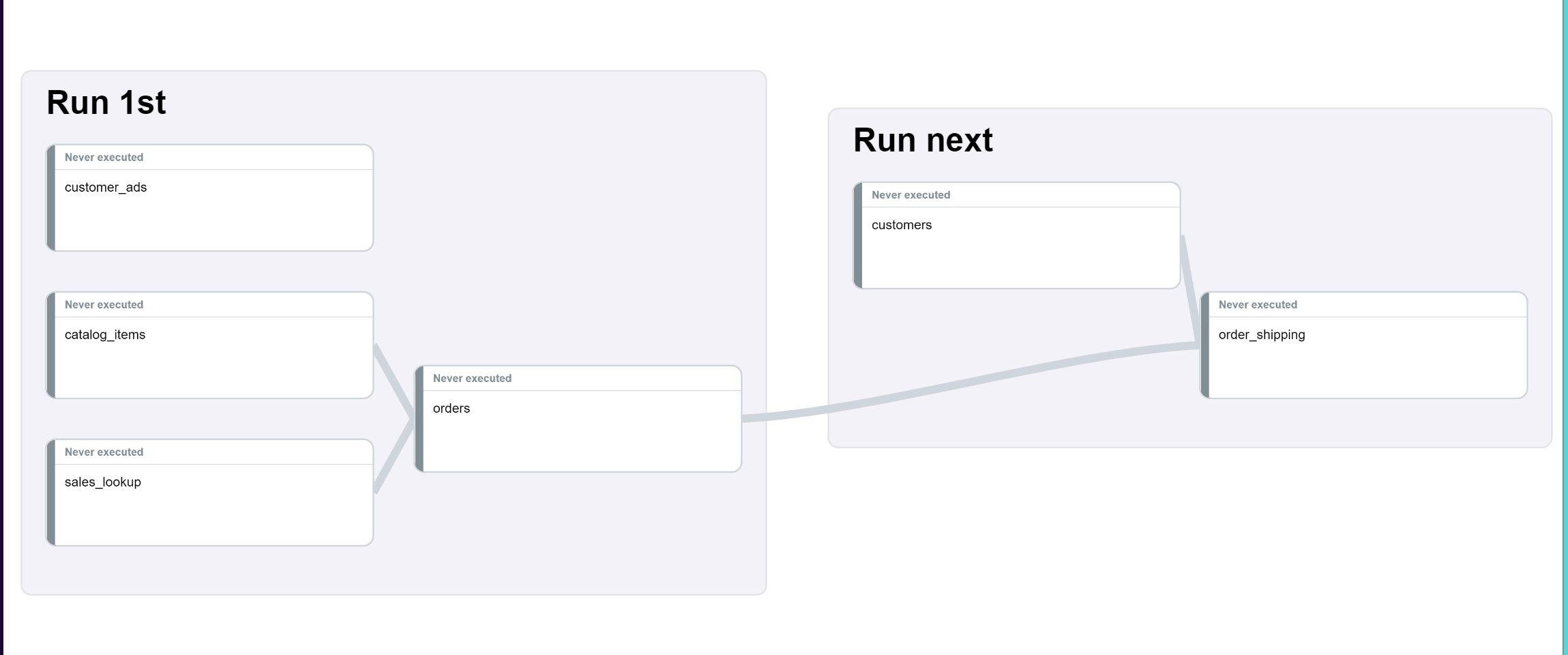
All the data in Run 1st is available at 04:00 but the customers data won’t be available until 09:00. The client can wait until 09:00 and then run all transforms, but if their finance team has a report which runs every day at 08:00, they would probably run the transforms as 2 jobs.
So, at 04:00 the transforms in the first job are run and as we can see order_shipping has 2 upstream dependencies, so that transform won’t run until those have completed. At 09:00 the other job starts and will first run customers and then order_shipping. order_shipping has an upstream dependency on orders, which means if that transform hasn’t completed, then it will need to wait before it can run.
If at any point during the execution of the transforms there is an error, then all downstream transforms will be skipped, as they cannot be executed - tables won’t be created, data will be missing, etc. On the other hand, transforms that are not downstream will run normally. So, if catalog_items failed, then orders will be skipped, but transforms not dependent on catalog_items would run normally. When the next job starts only customers can and will be run.
Advanced Scheduling & Dependencies
An advanced DAG example:
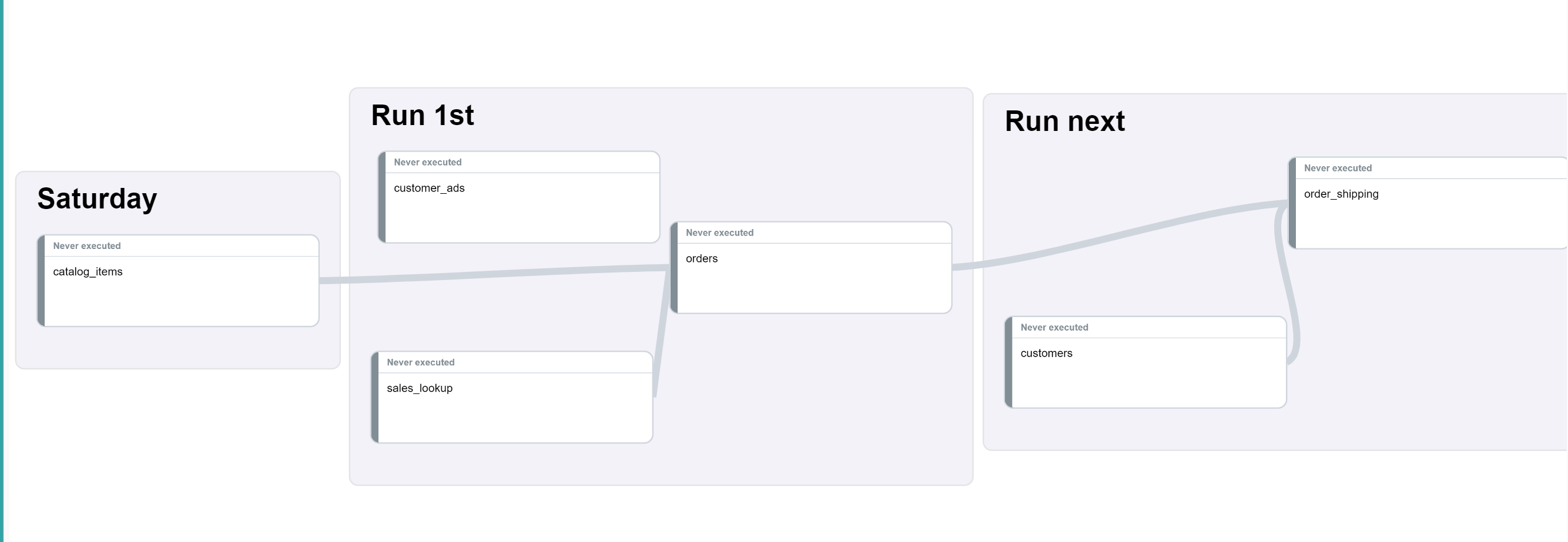
This is similar to the earlier example, but now we see one of the transforms will be run every Saturday, let’s say at 07:00. Some jobs are run less frequently but can be an upstream dependency of other tables.
If we apply the logic mentioned above, every time Run 1st runs it will wait for the Saturday, which would mean the whole pipeline would only ever complete on a Saturday.
Scheduling Transforms
To schedule a transform, select the transform you wish to schedule, then click the more menu (...) select Settings.

Scroll to the bottom and open Schedule, then add the repeating schedule that works for the transform.
If individual transforms within groups are required to be scheduled at specific times, then the group schedule can be overwritten. However, if the transform has upstream dependencies, then that transform is locked into being dependency-based. It is recommended to schedule on the group level, so that the Kleene app scheduler can determine the order of execution and run the jobs when the upstream jobs have finished, as opposed to scheduling transforms to run at specific times and run the risk of transform jobs overlapping.
We recommend scheduling by transform group
Technical Details
Scheduling Logic
In the app you can apply a schedule directly to a transform, or you can apply a schedule to a transform group.
Using the basic DAG as an example:
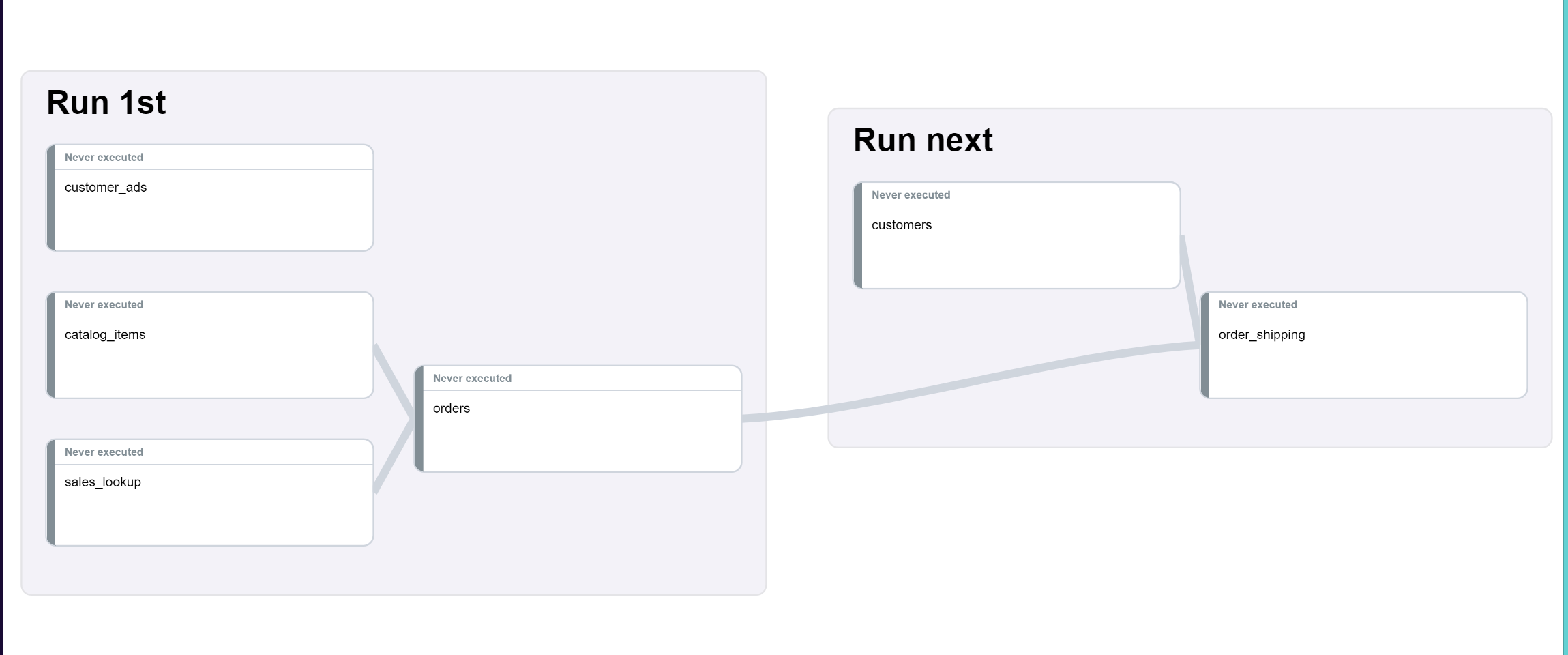
If you applied a schedule to the Run next group, the schedule would only be applied to customers as that one doesn’t have any upstream dependencies.
When you attach a schedule directly to a transform, dependencies are not ignored. If you were to add a schedule to order_shipping it would execute at those times, as well as on the schedule of the upstream transforms it is dependent on.
If a group has a schedule, individual transforms within that group cannot be scheduled. Similarly, if an individual transform is scheduled, then the group to which it belongs cannot be scheduled.
Currently, we allow transforms to be scheduled based on a daily, hourly, or minute-based interval, but we do not allow them to be scheduled to run more frequently than once an hour.
Dependency Logic
During execution a DAG of all downstream transforms which can be executed will be created. If one of the downstream transforms or their dependencies is scheduled to run later in the day, then that part of the DAG will be removed.
Taking the DAG above as an example, if you scheduled the Run 1st group to run every day at 04:00 and 12:00 and Run next every day at 09:00, the executions would be:
04:00 - Run 1st: sales_lookup, customer_ads, catalog_items, orders
09:00 - Run next: customers, order_shipping
12:00 - Run 1st: sales_lookup, customer_ads, catalog_items, orders, customers, order_shipping
Others
Manual and scheduled executions have different behaviours. Scheduled executions will always execute transforms downstream. However, if you manually run a transform in the app, you can choose to execute upstream, downstream, or only the transform itself. Choosing to run a single transform manually is particularly useful for testing purposes.
Something else to be aware of - paused transforms can be run manually but will be ignored in a scheduled execution.
Additionally, if multiple transforms from the DAG can be executed simultaneously, only some of them will be selected at random for execution. The number of transforms selected depends on the connection count limit, which is set to 2 by default.
Updated 8 months ago