
Transforms
Where all you SQL code lives
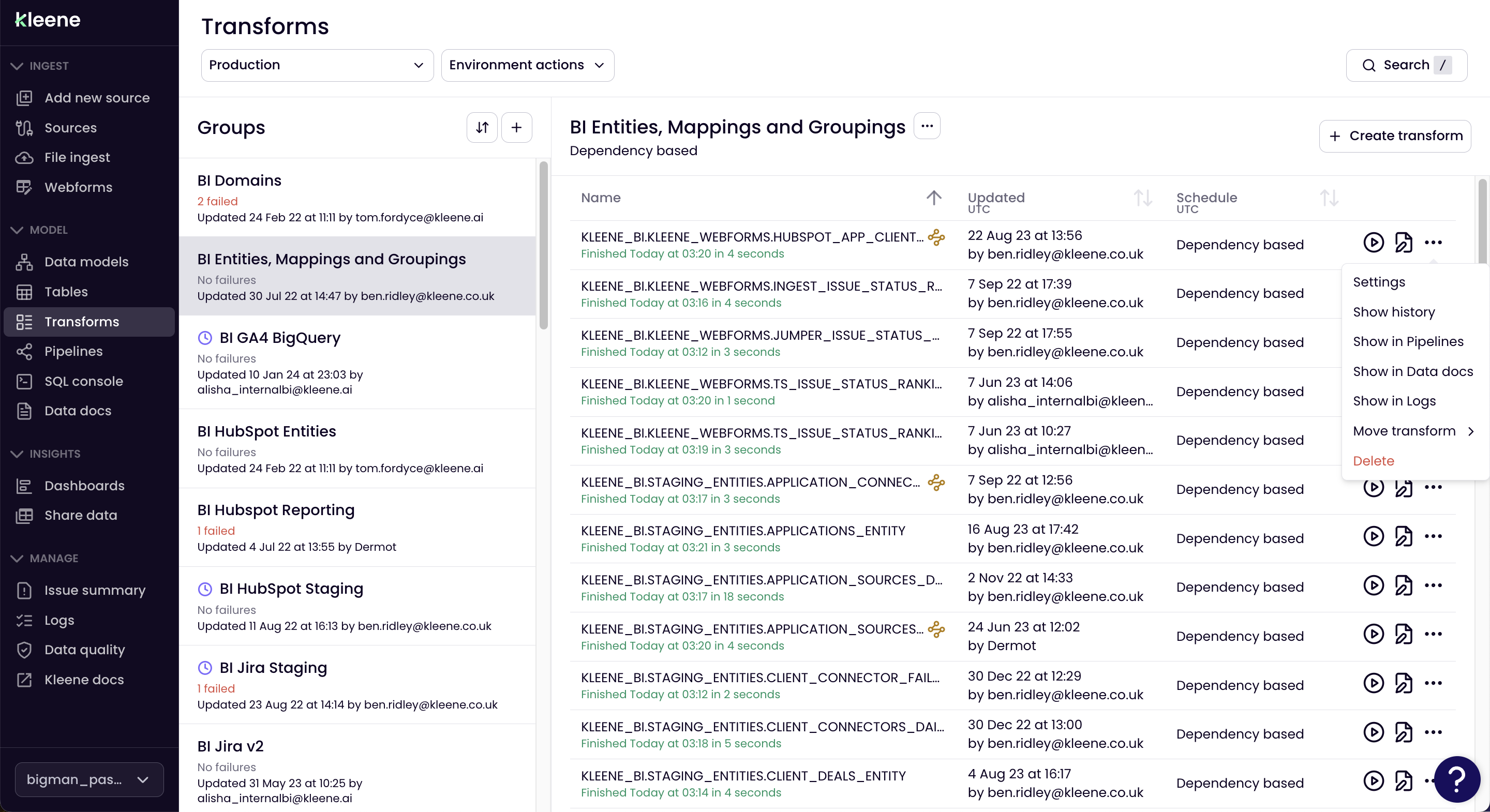
This page is where you'll find the groups and SQL transforms within those groups.
From here you can also -
- Edit the transform in the SQL Console
- Run Upstream, Run Downstream or Run this one
- Edit the settings and schedule
- Revert to a previous version
- Open the transform in Pipelines, Data Docs, and Logs
Updated 8 months ago
Did this page help you?